07 июля 2023
Python
У Django есть возможность расширить функционал списка объектов дополнительными функциюми через управление списком функций actions
Например вот так выглядит расширение для чистки кеша
def update_cdn_cache(modeladmin, request, queryset):
for obj in queryset:
obj.file.clean_cache()
А затем эта функция добавляется в класс админки
class ImageAdmin(admin.ModelAdmin):
actions = (update_cdn_cache, show_cdn_url)
По умолчанию эти функции отображаются над списком объектов в выпадающем списке и имена формируются из названий
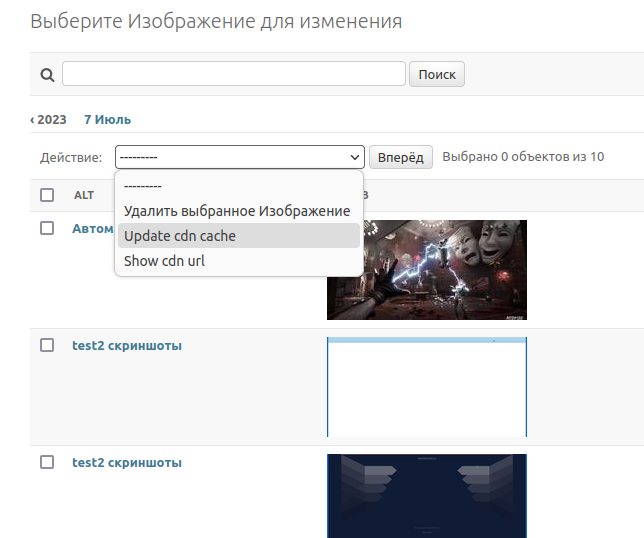
Видно, что выглядит для наглядности необходимо добавить описание и делается это путём добавления свойства short_description для каждой функции actions, но выглядит этот вариант не красиво, особенно когда расширений админки много
def update_cdn_cache(modeladmin, request, queryset):
for obj in queryset:
obj.file.clean_cache()
update_cdn_cache.short_description = _("Remove CDN file")
Чтобы избежать такого способа можно применить параметризованный декоратор
def add_short_description(short_description: str):
def decorator(admin_action):
def wrapper(*args, **kwargs):
return admin_action(*args, **kwargs)
wrapper.__name__ = admin_action.__name__ # принудительная смена названия функции
wrapper.short_description = _(short_description) # перевод описания
return wrapper
return decorator
с таким декоратором код выглядит более читаемым
@add_short_description("Remove CDN file")
def update_cdn_cache(modeladmin, request, queryset):
for obj in queryset:
obj.file.clean_cache()
@add_short_description("Show CDN file")
def show_cdn_url(modeladmin, request, queryset):
for obj in queryset:
print(obj.file.image())
Результат будет явно приятнее
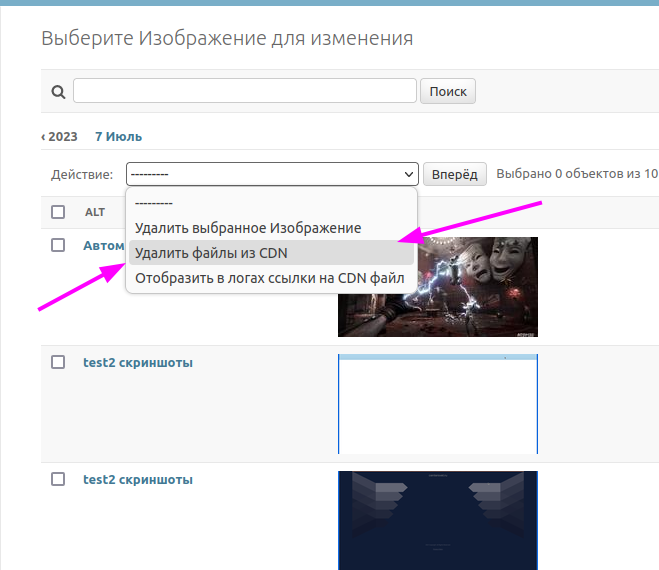
Есть ещё один способ, встроенный в Django
@admin.action(description=_("Enable user"))
def make_published(modeladmin, request, queryset):
queryset.update(is_active=True)