
22 ноября 2024 Bash bash hotkeys history comman edit comman
Вчера получил комментарий, о том, что в Баше есть Ctrl+l для быстрой очистки буфера и я понял, что пользуюсь только хоткеями навигации по строке и поиска. Так вот они эти быстрые клавиши
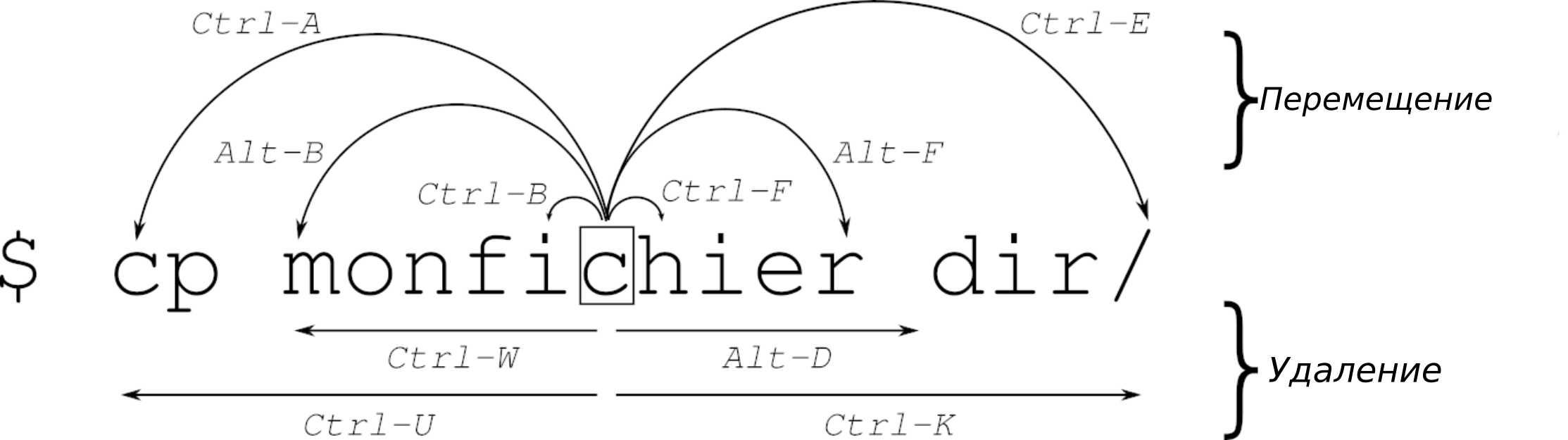
Команды для перемещения по командной строке
| Команда | Описание |
|---|---|
| Ctrl + a | Перейти в НАЧАЛО строки команд. |
| Ctrl + e | Перейти в КОНЕЦ строки команд. |
| Ctrl + b | Переместить курсор на один символ назад. |
| Ctrl + f | Переместить курсор на один символ вперед. |
| Alt + f | Переместить курсор ВПЕРЕД на одно слово. |
| Alt + b | Переместить курсор НАЗАД на одно слово. |
| Ctrl + xx | Переключение между началом строки и текущей позицией курсора. |
| Ctrl + ] + x | Где x — любой символ, переместить курсор к следующему вхождению x. |
| Alt + Ctrl + ] + x | Где x — любой символ, переместить курсор к предыдущему вхождению x. |
Редактирование и контроль командной строки
| Команда | Описание |
|---|---|
| Ctrl + d | Удалить символ под курсором. |
| Ctrl + h | Удалить символ перед курсором. |
| Ctrl + u | Удалить все до курсора (вырезать). |
| Ctrl + k | Удалить все после курсора (вырезать). |
| Ctrl + w | Удалить слово перед курсором. |
| Alt + d | Удалить слово от курсора. |
| Ctrl + y | Вставить вырезанный текст. |
| Ctrl + i | Автодополнение команды, как клавиша Tab. |
| Ctrl + l | Очистить экран (аналог команды clear). |
| Ctrl + c | Прервать выполняющийся процесс. |
| Ctrl + d | Выйти из оболочки (если строка пуста). |
| Ctrl + z | Перевести текущий процесс в фоновый режим. |
| Ctrl + _ | Отменить последнее действие. |
| Ctrl + x Ctrl + u | Отменить последнее изменение (аналог Ctrl + _). |
| Ctrl + t | Поменять местами два символа перед курсором. |
| Esc + t | Поменять местами два слова перед курсором. |
| Alt + t | Поменять местами текущее и предыдущее слово. |
| Alt + [Backspace] | Удалить ПРЕДЫДУЩЕЕ слово. |
| Alt + ? | Показать список файлов/папок в текущем пути. |
| **Alt + *** | Вывести все файлы/папки текущего пути как параметры. |
| Alt + . | Вывести ПОСЛЕДНИЙ АРГУМЕНТ предыдущей команды. |
| Alt + c | Сделать первую букву слова заглавной. |
| Alt + u | Сделать все буквы слова заглавными. |
| Alt + l | Сделать все буквы слова строчными. |
| ~[Tab][Tab] | Показать всех пользователей. |
| $[Tab][Tab] | Показать все системные переменные. |
| @[Tab][Tab] | Показать все записи из /etc/hosts. |
| [Tab] | Автодополнение. |
| cd - | Перейти в ПРЕДЫДУЩУЮ рабочую директорию. |
Работа с историей баша
| Команда | Описание |
|---|---|
| Ctrl + r | Искать команду в истории (обратный поиск). |
| Ctrl + s | Искать команду в истории (прямой поиск). |
| Ctrl + p | Предыдущая команда (аналог стрелки вверх). |
| Ctrl + n | Следующая команда (аналог стрелки вниз). |
| Ctrl + o | Выполнить команду, найденную через Ctrl + r. |
| Ctrl + g | Выйти из режима поиска в истории. |
| !! | Выполнить ПРЕДЫДУЩУЮ команду (например, sudo !!). |
| !vi | Выполнить ПРЕДЫДУЩУЮ команду, начинающуюся с vi. |
| !vi:p | Вывести команду из истории, начинающуюся с vi. |
| !n | Выполнить команду под номером n в истории. |
| !$ | Последний аргумент предыдущей команды. |
| !^ | Первый аргумент предыдущей команды. |
| ^abc^xyz | Заменить первое вхождение abc на xyz в последней команде и выполнить её. |
| Alt + < | Перейти к первой строке в истории. |
| Alt + > | Перейти к последней строке в истории. |
Завершение задач
Список задач можно вывести с помощью команды jobs. Для завершения задачи используйте:
kill %n
Где n — номер задачи. Например:
kill %1