04 октября 2023 Linux docker ftp proFTPD
Современный backend может не содержать на физическом сервере своих привычных файлов, там может даже не было СУБД и Веб-сервера потому что вся система размещается в контейнерах Docker
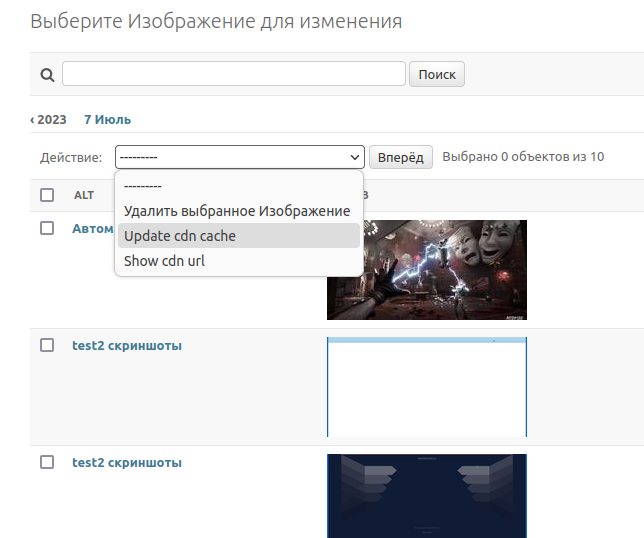
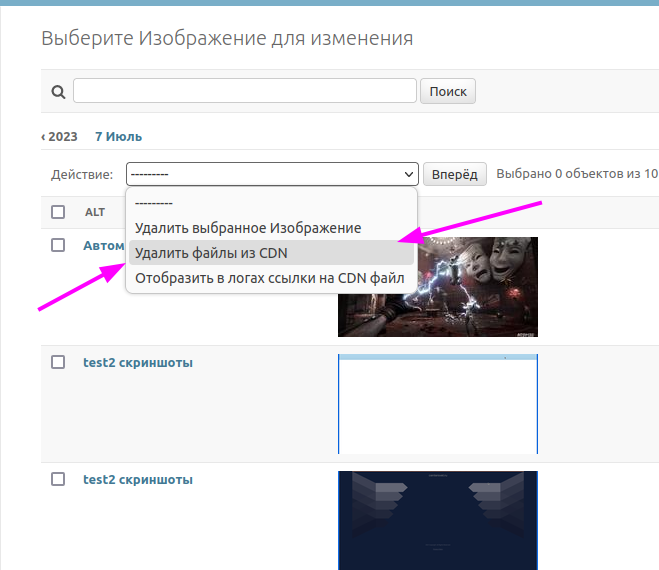
Для того чтобы предоставить доступ к файлам в таком контейнере можно воспользовать образом proFTPD и включить его в конфигурацию docker-compose
Ниже представлена настройка такого контейнера
ftp:
image: instantlinux/proftpd
container_name: ${APP_NAME}-ftp
ports:
- "2100:21"
- "30091-30100:30091-30100"
env_file: .env
volumes:
- ./ftp/secrets:/run/secrets
- ./site:/home/site/
environment:
- PASV_ADDRESS=0.0.0.0
- ANONYMOUS_DISABLE=on
- TZ=Europe/Moscow
- SFTP_ENABLE=off
- PASV_MAX_PORT=30100
- PASV_MIN_PORT=30091
так же предполагается наличие .env файла в котором необходимо определить следующие переменные
FTPUSER_UID=1000
FTPUSER_NAME=ftp_user
FTPUSER_PASSWORD_SECRET=Yhatztna7%$4A8hag
Переменная FTPUSER_UID должна быть равна ID текущего пользовать от имени которого запускается контейнер
Переменные FTPUSER_NAME и FTPUSER_PASSWORD_SECRET ипользуется для генерации пароля и поиска этого пароля в специальном файле в директории /run/secrets
Дело в том, что proFTPD использует пароли в определённом формате, для нормальной работы необходимо сгенерировать пароль и положить в специальный файл, который будет подмотирован в образ proFTPD
python3 -c "import crypt,random,string; print(crypt.crypt('$FTPUSER_PASSWORD_SECRET', '\$6\$' + ''.join( [random.choice(string.ascii_letters + string.digits) for _ in range(16)])))" > ftp/secrets/$FTPUSER_PASSWORD_SECRET
в результате получится вот такой файл с паролем
cat ftp/secrets/Yhatztna7%\$4A8hag
$6$XyHVN6aqgQvgj7Vv$Ac/9hKk0WYOmYPPh/hcG/yLvMAAgi91.k5lC2U4Dx/1PEe0KtW8NsLOhN6GBzcX8TKQPF51JHmyBX580pZ9.A0
Если хочется дополнительных опцией автозапуска то достаточно изучить файл инициализации контейнера
docker-compose exec ftp cat /usr/local/bin/entrypoint.sh