01 октября 2024 02 октября 2024 СуБД
Настройка определяются практически в одном месте, на главном сервер, а дочерний сервер отличается от главного только наличием сигнального файла postgres-slave1/standby.signal в директории с данными на подчинённом сервере. То-есть, сначала конфигурируется главный сервер так, чтобы в случае обнаружения файла standby.signal он стал вторичным, но перед этим, на том сервере который должен стать вторичным необходимо удалить базу и восстановить с первичного, а затем создать файл standby.signal
Продемонстрирую данный процесс с помощью конфигурации оркестра докер контейнеров, в этих контейнерах можно гибко управлять директориями базы данных и прочими характеристиками
Для начала создам файл docker-compose.yml и определю там запуск и настройки главного сервера
version: "3.9"
services:
master:
image: postgres:14
container_name: master
volumes:
- ./postgres-master:/var/lib/postgresql/data/
- ./wals:/var/lib/postgresql/archive/
env_file:
- .env
так же небходимо создать файл с настройками по умолчанию для postgres
POSTGRES_USER=test
POSTGRES_PASSWORD=test++test
POSTGRES_DB=test
POSTGRES_INITDB_ARGS=
создадим директории для хранения данных СУБД вне контейнеров
mkdir {postgres-master,postgres-slave1,postgres-slave2}
создадим директорию для хранения wal файлов
mkdir wals
Запускаем главный сервер и проверяем его работу
docker-compose up -d
docker-compose exec master psql -U test # войти в консоль главным пользователем и посмотреть список баз
create database test111; -- создать базу test111
\l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+-------+----------+------------+------------+-------------------
postgres | test | UTF8 | en_US.utf8 | en_US.utf8 |
template0 | test | UTF8 | en_US.utf8 | en_US.utf8 | =c/test +
| | | | | test=CTc/test
template1 | test | UTF8 | en_US.utf8 | en_US.utf8 | =c/test +
| | | | | test=CTc/test
test | test | UTF8 | en_US.utf8 | en_US.utf8 |
test111 | test | UTF8 | en_US.utf8 | en_US.utf8 |
Готово, сервер работает. Теперь склонируем секцию настройки главного сервера в docker-compose.yml, назовём его slave1 и перезапустим клустер, а так же проверим какие базы имеются на подчинённом сервере
version: "3.9"
services:
master:
image: postgres:14
container_name: master
volumes:
- ./postgres-master:/var/lib/postgresql/data/
- ./wals:/var/lib/postgresql/archive/
env_file:
- .env
slave1:
image: postgres:14
container_name: slave1
volumes:
- ./postgres-slave1:/var/lib/postgresql/data/
- ./wals:/var/lib/postgresql/archive/
env_file:
- .env
Перезапуск клустера
docker-compose down
docker-compose up -d
docker-compose ps
NAME COMMAND SERVICE STATUS PORTS
master "docker-entrypoint.s…" master running 5432/tcp
slave1 "docker-entrypoint.s…" slave1 running 5432/tcp
Проверка баз на подчинённом сервере
docker-compose exec slave1 psql -U test
psql (14.13 (Debian 14.13-1.pgdg120+1))
Type "help" for help.
test=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+-------+----------+------------+------------+-------------------
postgres | test | UTF8 | en_US.utf8 | en_US.utf8 |
template0 | test | UTF8 | en_US.utf8 | en_US.utf8 | =c/test +
| | | | | test=CTc/test
template1 | test | UTF8 | en_US.utf8 | en_US.utf8 | =c/test +
| | | | | test=CTc/test
test | test | UTF8 | en_US.utf8 | en_US.utf8 |
(4 rows)
Тут видно, что на подчинённом сервере отсутствует таблица test111, это произошло потому, что slave1 пока что не является подчинённым сервером, так как она ещё не настроен
Для того чтобы slave1 стал подчинённым необходимо разрешить главному серверу принимать внешние подключения от подчинённых серверов.
Для этого необходимо на главном сервере создать нового пользоваетля с правами репликации и разрешить этого пользоватлю внешние подключения
create user newuser replication login PASSWORD '2024';
теперь необходимо разрешить удалённый доступ этому пользователю
Для этого необходимо на главном сервере в файле postgres-master/pg_hba.conf добавить разрешение. Адрес 0.0.0.0/0 я использую для среды докер контейнером, потому там адрес контейнером могут менять, по этому будем принимать все входящие
host replication newuser 0.0.0.0/0 md5
Перезапускае главный сервер и проверяем возможность доступ с починённого
docker-compose restart
docker-compose exec slave1 psql postgres://newuser:2024@master/test111 # тут я использую упрощённый способ формирования строки запрос в виде урла, такие урлы применяются во многих приложениях совместимых libpg
psql (14.13 (Debian 14.13-1.pgdg120+1))
Type "help" for help.
test111=> \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+-------+----------+------------+------------+-------------------
postgres | test | UTF8 | en_US.utf8 | en_US.utf8 |
template0 | test | UTF8 | en_US.utf8 | en_US.utf8 | =c/test +
| | | | | test=CTc/test
template1 | test | UTF8 | en_US.utf8 | en_US.utf8 | =c/test +
| | | | | test=CTc/test
test | test | UTF8 | en_US.utf8 | en_US.utf8 |
test111 | test | UTF8 | en_US.utf8 | en_US.utf8 |
(5 rows)
test111=>
Тут видно, что я из среды подчинённого сервера подключаюсь через внутренную сеть среды докер к терминалу главного сервера и там доступна новую базу данных
Теперь попробуем на подчинённом сервере загрузить резервную копию главного сервер
docker-compose exec slave1 pg_basebackup -d postgres://newuser:2024@master -v -D /tmp/base
Тут мы из среды подчинённого сервер подключаемся к главному и выкачиваем бекап в директорию /tmp/base
Если всё хорошо сработало, то пришло время настраивать отношения master слейв для клустера.
Для этого переопределим настройки главного сервера в файле sudo vim postgres-master/postgresql.conf
wal_level = replica
max_wal_senders = 5 # я указываю 5
archive_mode = on
wal_keep_size = 1024 # Обеспечивает хранение WAL файлов до передачи
hot_standby = on
archive_command = 'test ! -f /var/lib/postgresql/data/archive/%f && cp %p /var/lib/postgresql/archive/%f'
Строчку est ! -f /var/lib/postgresql/data/archive/%f && cp %p /var/lib/postgresql/archive/%f необходимо пояснить: эта строчка описывает комаду которая создаёт архивную копию WAL файл, в моём случае я копию её в директорию которая доступна снаружи конейнера: ./wals:/var/lib/postgresql/archive/
Затем уже для подчинёного сервера привести переменную primary_conninfo к такому виду, эта переменная редактируется в файле мастер сервера, но она будет игнорироваться мастеро
primary_conninfo = 'host=master port=5432 user=newuser password=2024'
Теперь необходимо на удалить все данные на подчинённом сервере в директории /var/lib/postgresql/data/ и на освободившееся место поместить бекап главного сервера с помощь утилиты pg_basebackup, но перед этим необходимо оставить подчинённй сервер постгрес
docker-compose stop slave1
docker-compose run slave1 rm -R /var/lib/postgresql/data/
Теперь скачиваем бека с главного сервера запускаем подчинённый
docker-compose run slave1 pg_basebackup -d postgres://newuser:2024@master -v -D /var/lib/postgresql/data
А теперь самое главное, создание файла сигнала, обнаружив который, обычный узел Postgres превращается в ведомй
sudo touch postgres-slave1/standby.signal
Запускаем подчнённый сервер и видим, что появилась база которая была создана на главном сервере
docker-compose start slave1
echo \\l | docker-compose exec -T master psql -U test
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+-------+----------+------------+------------+-------------------
postgres | test | UTF8 | en_US.utf8 | en_US.utf8 |
template0 | test | UTF8 | en_US.utf8 | en_US.utf8 | =c/test +
| | | | | test=CTc/test
template1 | test | UTF8 | en_US.utf8 | en_US.utf8 | =c/test +
| | | | | test=CTc/test
test | test | UTF8 | en_US.utf8 | en_US.utf8 |
test111 | test | UTF8 | en_US.utf8 | en_US.utf8 |
(6 rows)
Теперь создадим новую скопируем живую базу на главный сервер клустера
# создание новой базы
docker-compose exec master createdb -U test global-art
# клонирование живой базы с одного из моих тестовых серверов
pg_dump -c globalart | docker-compose exec -T master psql -U test global-art
# проверка структуры новой базы на главном сервере
echo \\dt | docker-compose exec -T master psql -U test global-art
List of relations
Schema | Name | Type | Owner
--------+------------------------------------+-------+-------
public | auth_group | table | test
public | auth_group_permissions | table | test
public | auth_permission | table | test
public | auth_user | table | test
public | auth_user_groups | table | test
public | auth_user_user_permissions | table | test
public | catalog_accessory | table | test
public | catalog_accessory_subproducts | table | test
public | catalog_additionalfile | table | test
Тут видно, что главном сервере появилась новая база данных и в этой базе есть таблицы. Подсчитаем контрольную сумму этой базы с помощью md5
docker-compose exec master pg_dump -U test global-art |md5sum
164858e3f201d1f6261c3fad4b5ff59a -
Видим, что контрольная сумма базы на главном сервере равна 164858e3f201d1f6261c3fad4b5ff59a
Теперь, предполагая, что главный сервер клустера передал изменения на подчинённый сервер проверим контрольную сумму базы на подчинённом сервере slave1
docker-compose exec slave1 pg_dump -U test global-art |md5sum
164858e3f201d1f6261c3fad4b5ff59a -
Видим, что базы одинаковые. То-есть, репликация происходит в нормальном режиме
Визуализация работы клустера
Добавление новых записей в главной базе
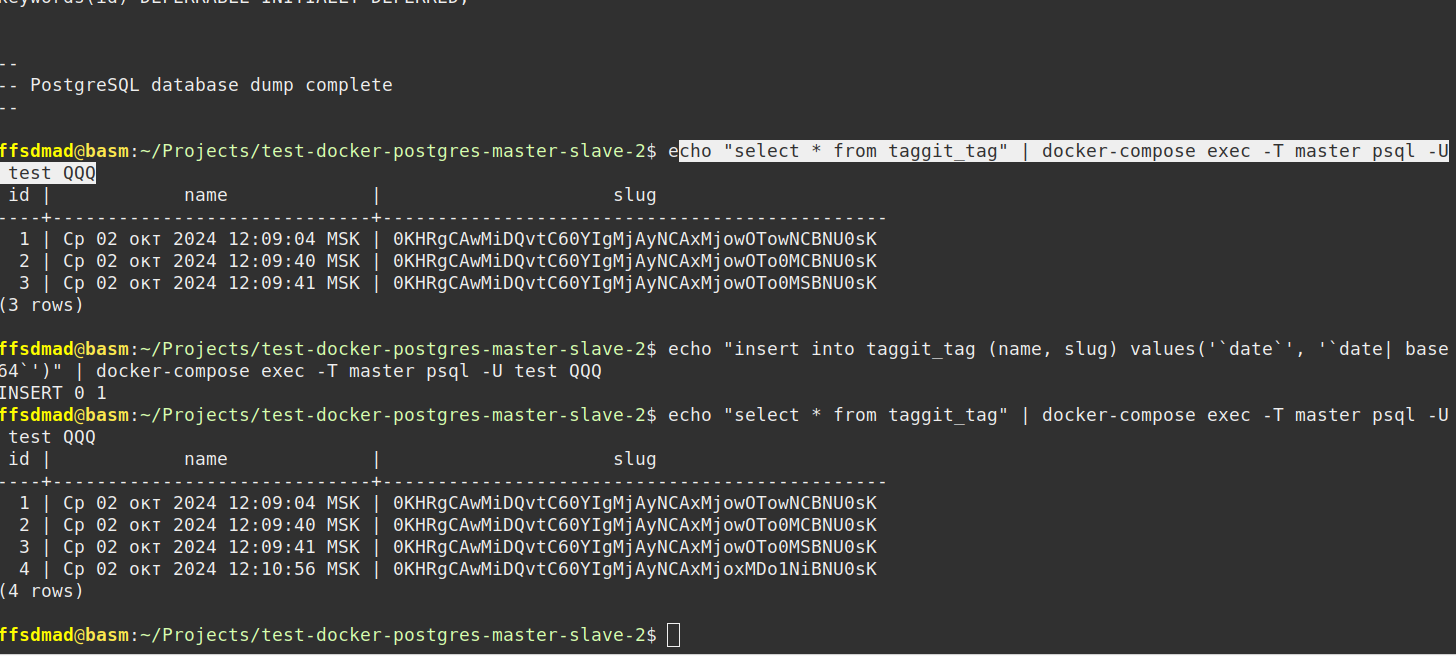
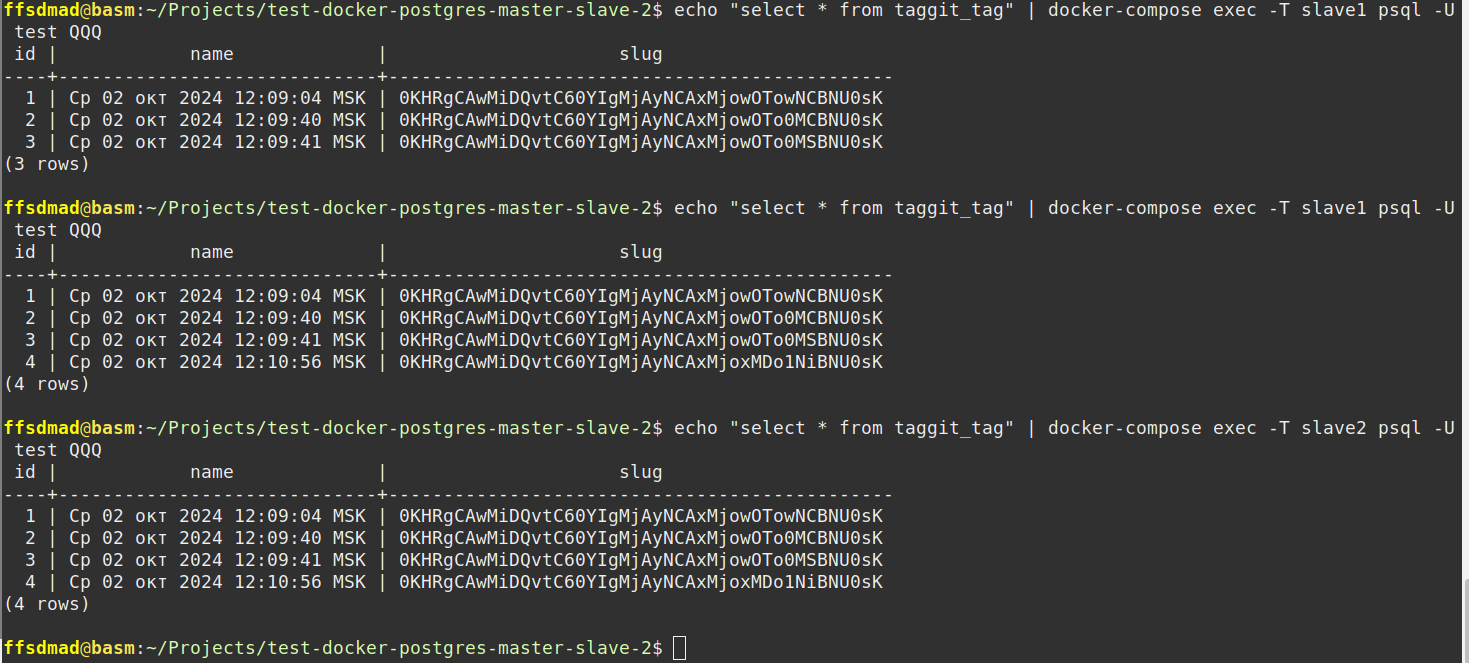
Проверка добавления новых записей на подчинённых серверах
Логи работы клустера